Introdução à Inteligência Artificial

Pedro Oliveira
Lead Web Developer
28 min read • May 21, 2026
Explora os fundamentos da Inteligência Artificial (IA) neste guia para iniciantes, que aborda os conceitos-chave, os marcos históricos mais importantes, os tipos de modelos existentes e um exercício prático para construíres o teu primeiro modelo de IA simples para computer vision.

introduction-to-artificial-intelligence-load-blog
A Inteligência Artificial (IA) tem vivido avanços enormes nos últimos anos, a um ponto em que pode ser ao mesmo tempo fascinante e completamente avassaladora para quem está a tentar perceber, aprender e fazer algo com ela. Neste artigo, damos um passo atrás e olhamos para alguns dos conceitos mais importantes dentro do universo da IA, mergulhamos na sua história, exploramos os tipos de modelos e arquiteturas mais comuns, e terminamos com a criação de um modelo simples para resolver um problema básico de visão computacional.
O que é a Inteligência Artificial?
Em 2018, a Comissão Europeia definiu a IA da seguinte forma: “A inteligência artificial (IA) refere-se a sistemas que exibem comportamento inteligente ao analisar o seu ambiente e tomar ações — com algum grau de autonomia — para atingir objetivos específicos. Os sistemas baseados em IA podem ser puramente baseados em software, atuando no mundo virtual (por exemplo, assistentes de voz, software de análise de imagem, motores de pesquisa, sistemas de reconhecimento de voz e facial) ou a IA pode estar incorporada em dispositivos de hardware (por exemplo, robôs avançados, carros autónomos, drones ou aplicações de Internet das Coisas).”
Por outras palavras, podemos pensar na IA como a tecnologia que permite a qualquer tipo de máquina — seja um smartphone, um carro, um drone ou uma câmara — simular a inteligência humana e a capacidade de resolução de problemas.
História
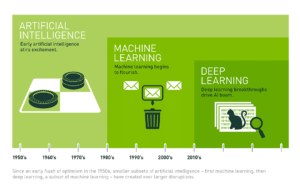
Apesar de algumas publicações e descobertas iniciais, o conceito de inteligência artificial só ganhou verdadeiro impulso por volta de 1950, quando pioneiros como Alan Turing lançaram as bases com conceitos como o Teste de Turing — um teste para avaliar a capacidade de uma máquina exibir comportamento inteligente. Nos anos seguintes, foi desenvolvido um programa para jogar damas, assim como o ELIZA, um chatbot que simulava conversas e demonstrou o potencial da IA em imitar interações humanas. Apesar de todos estes avanços, os anos 70 trouxeram um período de incerteza e financiamento limitado, conhecido como o “Inverno da IA”.
Ainda assim, o interesse pela IA voltou a ganhar força nos anos 80 com o surgimento dos sistemas especialistas, que imitavam processos de tomada de decisão humanos. A década de 90 ficou marcada pela vitória do Deep Blue da IBM contra o campeão mundial de xadrez Garry Kasparov, enquanto os anos 2000 viram o lançamento do Roomba da iRobot — um robô autónomo capaz de aspirar o chão enquanto navega e evita obstáculos — e um crescente interesse nos carros autónomos. Em 2012, o “ImageNet Large Scale Visual Recognition Challenge” foi vencido por um modelo de deep learning desenvolvido por Alex Krizhevsky, o que se revelou um ponto de viragem decisivo, já que as abordagens existentes ao reconhecimento de imagem foram abandonadas em favor do deep learning.
2017 trouxe outro momento marcante, quando a Google publicou o artigo “Attention Is All You Need”, que introduziu o conceito de modelos transformer e revolucionou o campo do processamento de linguagem natural (NLP). No ano seguinte, a OpenAI lançou o GPT-1, a primeira versão do generative pre-trained transformer (GPT). A partir daí, a IA generativa começou a dominar, dando origem a produtos como o ChatGPT, DALL-E, GitHub Copilot, Midjourney, Gemini, Claude, entre muitos outros. Todos estes avanços tiveram um impacto significativo em diversas áreas, tornando a IA uma parte integrante da tecnologia moderna e do quotidiano.
Machine learning
O machine learning (ML) é um subconjunto da IA que se foca no desenvolvimento de algoritmos e modelos estatísticos que aprendem gradualmente a resolver problemas específicos, reconhecendo padrões, ligações e correlações em conjuntos de dados, sem necessidade de instruções explícitas. Existem cinco tipos diferentes de técnicas de machine learning, cada uma com características e aplicações distintas: supervised learning, unsupervised learning, semi-supervised learning, self-supervised learning e reinforcement learning.
Supervised learning
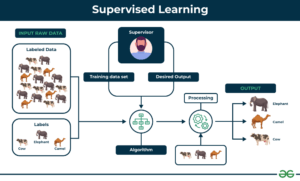
O supervised learning é a técnica de machine learning mais comum, onde os modelos são treinados com um dataset rotulado, ou seja, a variável alvo ou de resultado é conhecida. Num exemplo em que tens imagens de gatos e cães, o dataset fornece o rótulo correto (gato ou cão) para cada imagem.
Unsupervised learning
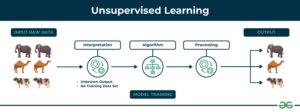
O unsupervised learning é um paradigma em que um algoritmo descobre padrões e relações a partir de dados não rotulados. O objetivo principal é frequentemente identificar padrões ocultos, semelhanças ou clusters dentro dos dados, que podem depois ser utilizados para diversos fins, como exploração de dados, visualização, redução de dimensionalidade, entre outros.
Semi-supervised learning
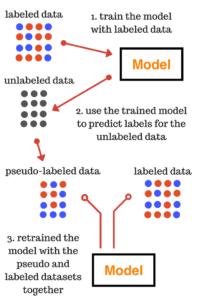
O semi-supervised learning é uma técnica que se situa entre o supervised e o unsupervised learning, uma vez que utiliza dados tanto rotulados como não rotulados. Começa por desenvolver e treinar um modelo com os dados rotulados disponíveis, depois usa esse modelo para prever o resultado dos dados não rotulados, transformando-os em dados pseudo-rotulados e, por fim, volta a treinar o modelo com a combinação dos dados rotulados e pseudo-rotulados. Esta técnica é particularmente útil e eficaz quando obter dados rotulados é dispendioso, moroso ou requer muitos recursos.
Self-supervised learning
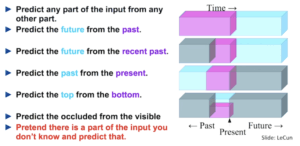
O self-supervised learning é o processo em que o modelo se treina a si próprio para aprender uma parte do input a partir de outra parte do mesmo. Neste processo, problemas de unsupervised learning são transformados em problemas de supervised learning através da geração automática de rótulos. Imagina que tens um dataset com a frase “A capital de Portugal é Lisboa.” Esta frase por si só não é muito útil, mas pode ser usada como rótulo ou resultado esperado para outras frases como “A capital de <blank> é Lisboa.” e “A capital de Portugal é <blank>.”. Para uma explicação mais detalhada, recomendo que vejas este vídeo, que contém uma excelente explicação deste processo.
Reinforcement learning
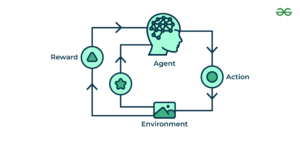
O reinforcement learning é um método de aprendizagem utilizado para treinar algoritmos através de um sistema de recompensa e punição. Para o aplicar, um agente executa ações num ambiente específico para atingir um objetivo pré-definido. O agente é recompensado ou penalizado pelas suas ações com base numa métrica estabelecida, incentivando-o a continuar as boas práticas e a abandonar as más.
Este processo é bastante semelhante ao de ensinar um cão a obedecer às tuas ordens. Quando o cão executa corretamente uma tarefa, recompensa-o com um petisco ou o brinquedo favorito; quando falha, “punis”-o ao não lhe dar recompensa e mostrando-lhe o que deveria ter feito.
Deep Learning
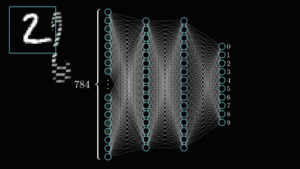
O deep learning (DL) é um subconjunto do ML que utiliza redes neurais com múltiplas camadas, conhecidas como deep neural networks, para aprender a partir de dados. Estas redes neurais são inspiradas na nossa compreensão da biologia do cérebro humano e tentam simular as suas complexas capacidades de tomada de decisão.
Consoante a tarefa a resolver, existem vários tipos de redes neurais que podem ser utilizados, como convolutional neural networks (CNNs), recurrent neural networks (RNNs), transformers, autoencoders, generative adversarial networks (GANs), diffusion, entre outros. Vamos percorrer cada um deles e perceber como funcionam e onde podem ser aplicados.
Convolutional neural networks (CNNs)
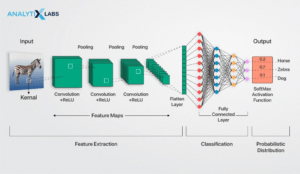
As convolutional neural networks (CNNs) especializam-se no processamento de dados com uma topologia em grelha (como uma imagem) e são frequentemente utilizadas em tarefas como reconhecimento de imagem e vídeo, classificação de imagens e deteção de objetos. São maioritariamente compostas por camadas convolucionais, camadas de pooling e camadas fully connected. As camadas convolucionais aplicam um conjunto de filtros que percorrem a imagem de entrada, realizando uma operação de convolução que cria feature maps que destacam vários aspetos da imagem, como arestas, texturas ou padrões. As camadas de pooling, como o max pooling, reduzem as dimensões espaciais dos feature maps, diminuindo a carga computacional e o número de parâmetros da rede neural. As camadas fully connected pegam nas features extraídas pelas camadas convolucionais e de pooling e utilizam-nas para fazer a previsão final.
Recurrent neural networks (RNNs)
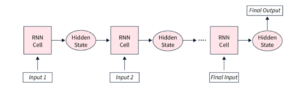
As recurrent neural networks (RNNs) são um tipo de rede neural utilizado para processar dados sequenciais. Usam unidades recorrentes para manter um hidden state que captura informação sobre os elementos anteriores na sequência, permitindo-lhes processar dados um passo de cada vez. Este hidden state, que funciona essencialmente como uma forma de memória, é atualizado a cada passo com base no input atual e no hidden state anterior, permitindo à rede aprender padrões e dependências nos dados. As RNNs podem ser usadas em tarefas como modelação de linguagem, tradução automática, análise de sentimentos, reconhecimento de voz e previsão de séries temporais. No entanto, na maioria destas tarefas, foram superadas por outro tipo de rede neural: os transformers.
Transformers
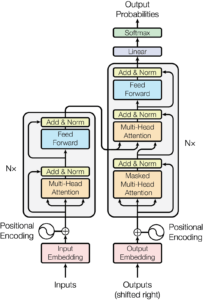
Os transformers são um tipo de rede neural que visa resolver tarefas de sequence-to-sequence, lidando de forma eficaz com dependências de curto e longo alcance. Utilizam um conjunto de abordagens matemáticas para detetar de que forma subtil elementos distantes numa série se influenciam e dependem uns dos outros. Os principais componentes dos transformers incluem:
- Input Embedding Layer: converte os dados de entrada em vetores de valores contínuos, que são uma representação densa do input e capturam as propriedades relevantes, como propriedades semânticas e sintáticas para texto, ou características espaciais e visuais para imagens.
- Positional Encoding: fornece informação sobre a posição dos dados de entrada, permitindo ao modelo compreender as posições relativas dentro da sequência de input.
- Multi-Head Attention: permite ao modelo ponderar a relevância de diferentes partes dos dados de entrada, aplicando múltiplos attention heads em paralelo, capturando várias relações dentro dos dados.
- Feed-Forward Neural Networks: aprendem padrões complexos nos dados, transformando as representações produzidas pelo mecanismo de self-attention.
- Normalização e Residual Connections: ajudam a estabilizar o processo de treino ao normalizar os inputs de cada camada e ao permitir que os gradientes fluam diretamente do output de uma camada para o seu input, mitigando problemas como o vanishing gradient.
- Output Layer: responsável por produzir o output final do modelo, convertendo as representações vetoriais finais numa distribuição de probabilidade sobre os possíveis tokens de output, gerando a sequência de output final.
Os transformers são as redes neurais estado-da-arte para tarefas de NLP e são a base de muitos modelos avançados como o GPT, Gemini, Llama e Claude. Para além do NLP, também têm ganho popularidade e apresentado bons resultados em áreas como a visão computacional.
Autoencoders
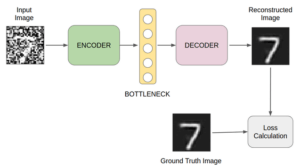
Os autoencoders são um tipo de rede neural que aprende a comprimir e codificar dados de forma eficaz e depois aprende a reconstruí-los a partir de uma representação comprimida, tentando que o resultado fique o mais próximo possível do original. Este tipo de rede neural é composto por um encoder, responsável por comprimir os dados de entrada numa representação de menor dimensão, e um decoder, responsável por reconstruir os dados de entrada a partir dessa representação comprimida. A rede é treinada para minimizar a loss function, que mede a diferença entre o input original e o output reconstruído. Os autoencoders são bastante versáteis e podem ser utilizados numa variedade de aplicações, como remoção de ruído em imagens, deteção de anomalias e compressão de dados.
Generative Adversarial Networks (GANs)
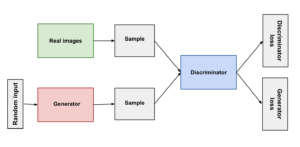
As Generative Adversarial Networks (GANs) são um tipo de rede neural capaz de gerar novos dados sintéticos que se assemelham a dados reais. Estas redes incluem um generator, que cria dados falsos a partir de ruído aleatório que recebe como input, e um discriminator, que tenta distinguir entre os dados reais provenientes do dataset de treino e os dados sintéticos produzidos pelo generator. Estas duas partes trabalham em competição, com o generator a melhorar as suas criações com base nas probabilidades que o discriminator produz, indicando se os dados são reais ou falsos. A rede é treinada com loss functions que medem o quão bem o generator consegue enganar o discriminator e o quão bem o discriminator distingue entre dados reais e falsos. Para perceber melhor este tipo de redes neurais, imagina um falsificador a tentar criar um quadro falso convincente, enquanto um perito em arte tenta detetar a falsificação. O falsificador melhora à medida que o perito se torna mais difícil de enganar, resultando num falso cada vez mais perfeito.
As GANs podem ser usadas para remover ruído de imagens, aumentar a resolução de imagens e gerar imagens realistas de paisagens, pessoas ou objetos que não existem de facto.
Diffusion
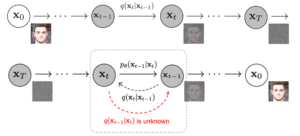
As redes neurais de diffusion especializam-se na geração de dados de alta qualidade ao adicionar progressivamente ruído a um dataset e depois aprender a inverter esse processo. Central ao seu funcionamento é o forward process, que adiciona gradualmente ruído gaussiano aos dados de entrada, e o reverse process, onde o modelo aprende a inverter o forward process ao remover gradualmente o ruído adicionado, levando à reconstrução dos dados originais ou à geração de novos dados. Este tipo de rede neural está por trás de modelos populares como o DALL-E, Midjourney, Stable Diffusion e Flux, sendo tipicamente utilizado para geração de imagens.
Practical Exercise
Agora que já cobrimos parte da história e dos fundamentos da IA, é hora de colocar a mão na massa. O nosso objetivo será desenvolver um modelo capaz de determinar se o animal numa determinada imagem é um gato ou um cão. Como vimos, as CNNs são excelentes a resolver tarefas relacionadas com imagens, por isso vamos construir uma CNN simples para atingir esse objetivo.
Ambiente
Para criar este modelo, vamos usar Jupyter Notebooks no Google Collab com Python 3.10. O Google Collab é uma excelente ferramenta de prototipagem, pois fornece um ambiente Python com a maioria dos pacotes conhecidos já instalados e permite utilizar uma unidade de processamento gráfico (GPU), o que acelera o processo de treino dos modelos. Embora o recomende vivamente, também podes usar Kaggle Notebooks, que é muito semelhante ao Google Collab, ou fazer tudo localmente na tua máquina. Se optares por isso, garante que o teu ambiente tem Python 3.10 e os seguintes pacotes instalados: numpy, Pillow, datasets e tensorflow.
Obtenção e carregamento de dados
Ter grandes quantidades de dados de qualidade é fundamental e vai ser determinante para o desempenho do teu modelo, por isso deves dedicar uma quantidade significativa de tempo à sua recolha e processamento. Existem várias formas de obter dados: podes procurá-los em fontes como o Hugging Face ou o Kaggle, usar dados que já tens, ou recolhê-los tu próprio se não encontrares nada adequado para a tarefa que queres que o teu modelo realize.
No nosso caso, vamos usar o pacote datasets do Hugging Face para carregar o seguinte dataset. Nota: o Hugging Face e o Kaggle são comunidades de IA fantásticas com imensos recursos disponíveis — recomendo vivamente que os guardes nos favoritos para referência futura.
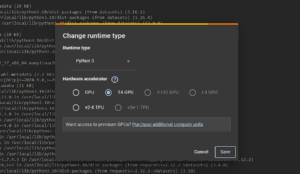
Antes de começarmos a escrever código, precisamos de garantir que estamos num runtime com acesso a uma GPU, pois isso vai acelerar o processo de treino do modelo. Para isso, vai a Runtime > Change Runtime Type e seleciona T4 GPU.
Com o runtime correto selecionado, vamos instalar o pacote datasets no nosso notebook. Para isso, executa o seguinte numa célula:

Após a instalação estar concluída, adiciona uma nova célula para importar a função load_dataset do pacote datasets e carregar o dataset específico que queremos. Neste caso, o nome do dataset é microsoft/cats_vs_dogs e o split que vamos usar é train, uma vez que é o único disponível. Alguns datasets já dividem os dados em dados de treino e dados de teste, mas não é o caso deste.

Agora que temos o dataset carregado, podemos inspecionar o seu conteúdo simplesmente chamando-o numa nova célula:

O resultado deverá ser o seguinte:
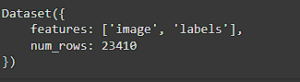
Isso significa que o dataset tem 23410 itens, onde cada item contém uma imagem e um rótulo. Podes inspecionar o dataset mais ao pormenor fornecendo o índice e a feature que queres ver. Por exemplo, adiciona uma nova célula com

para ver a imagem do primeiro item do dataset (para o índice 0, é a fotografia de um gato). Para ver o rótulo, podes fazer o mesmo, mas substituindo image por labels. Isso irá mostrar 0 se a imagem nesse índice for um gato ou 1 se for um cão.
Agora, vamos guardar as imagens no disco. Primeiro, vamos criar algumas pastas executando o seguinte numa nova célula:

E depois, numa outra célula:

Isto guarda todas as imagens de gatos na diretória dataset/cat e todas as imagens de cães na diretória dataset/dog.
Agora vamos dividir o dataset em dois conjuntos: treino e validação. Ao treinar um modelo, não deves usar todos os dados; em vez disso, usa uma quantidade maior para treino e uma menor para validação. Isto garante que o modelo não se foca apenas em aprender a partir de um dataset específico, mas também tem bom desempenho com dados novos que nunca viu. Neste cenário, vamos usar 75% dos dados para treino e 25% para validação.
Para dividir os dados, vamos usar uma função utilitária chamada image_dataset_from_directory do TensorFlow — o pacote que vamos usar para criar e treinar o nosso modelo, pois especializa-se em computação numérica, ML e DL em larga escala e outras cargas de trabalho de análise estatística e preditiva. Para isso, adiciona uma nova célula com o seguinte código:

Em resumo, este código:
- carrega as imagens e infere os rótulos a partir da diretória do dataset (labels, label_mode)
- converte as imagens para escala de cinzentos (color_mode)
- redimensiona as imagens para 128 de largura e 128 de altura (image_size)
- aplica padding às imagens para que não fiquem deformadas com o redimensionamento (pad_to_aspect_ratio)
- define o número de amostras processadas numa iteração de treino (batch_size)
- divide o dataset num conjunto de treino com 75% das imagens e num conjunto de validação com os restantes 25% (validation_split)
- define o formato de cada imagem (data_format)
Com os dados prontos, é hora de criar e treinar o nosso modelo.
Criação e treino do modelo
O TensorFlow inclui uma API de alto nível chamada Keras para facilitar a criação de modelos. O Keras permite-te construir modelos usando uma abordagem funcional ou sequencial. Para este exemplo, vamos usar a abordagem sequencial. Neste ponto, já podemos importar todas as camadas de que vamos precisar, bem como definir a input layer.

Na input layer, definimos o formato que vai aceitar — neste caso, a largura e altura da imagem (ambas 128) e o número de canais. Na nossa situação, vamos escolher 1 como número de canais porque estamos a usar imagens em escala de cinzentos; se tivesses imagens a cores, colocarias 3.
Agora que a input layer está definida, vamos adicionar alguns blocos convolucionais ao nosso modelo. Estes blocos serão formados por 4 tipos de camadas:
- Conv2D: camada que extrai features aplicando um conjunto de filtros treináveis, permitindo à rede detetar várias características como arestas, texturas e padrões.
- BatchNormalization: camada utilizada para melhorar a estabilidade e o desempenho das redes neurais, ao normalizar as ativações de cada camada.
- MaxPooling2D: camada que seleciona o valor máximo de cada região do feature map. É usada para fazer o downsampling dos feature maps produzidos pelas camadas convolucionais, reduzindo as dimensões espaciais e a complexidade computacional da rede.
- Dropout: camada que define aleatoriamente unidades de input para 0 com uma determinada frequência durante o treino. Ajuda a evitar que o modelo capture flutuações aleatórias nos dados de treino em vez dos padrões subjacentes (overfitting).


Após definir os blocos convolucionais, é hora de adicionar uma fully connected layer. Para isso, precisamos de adicionar duas camadas: Flatten e Dense. A camada Flatten transforma o output da última camada convolucional num vetor unidimensional, preparando-o para input na fully connected layer, enquanto a camada Dense — também conhecida como fully connected layer — é uma camada em que cada neurônio está ligado a todos os neurónios da camada anterior, permitindo ao modelo aprender relações complexas entre as features extraídas pelas camadas convolucionais. Estas 2 camadas devem ser seguidas de outra BatchNormalization e uma camada Dropout.

Para concluir a estrutura do nosso modelo, falta apenas a output layer. Esta será outra camada Dense com 1 unidade e sigmoid como função de ativação, uma vez que estamos a lidar com uma classificação binária (0 para gato e 1 para cão). Se quisesses classificar mais animais — gato, cão, pássaro e peixe, por exemplo — precisarias de aumentar as unidades da camada para 4 (o número de tipos de animais) e mudar a função de ativação para softmax.

Com a estrutura do modelo definida, é hora de o compilar. Para isso, adiciona uma nova célula com o seguinte:

Neste passo, definimos a loss function — uma componente fundamental que quantifica a diferença entre as previsões do modelo e os valores alvo reais —, o optimizer — responsável por atualizar os parâmetros da rede neural durante o treino para minimizar a loss function — e as metrics — funções utilizadas para avaliar o desempenho do modelo. Num cenário com mais de 2 tipos de animais, deverias usar categorical_crossentropy em vez de binary_crossentropy.
Estamos quase prontos para treinar o modelo, mas primeiro vamos definir algumas callback functions que serão chamadas durante o processo de treino para o melhorar:

A primeira callback (ReduceLROnPlateau) vai reduzir o learning rate quando a métrica monitorizada (val_loss) deixar de melhorar, de acordo com o fator definido, até atingir o valor mínimo permitido (min_lr). O learning rate determina o quanto os pesos da rede neural se alteram no contexto da otimização enquanto se minimiza a loss function.
A segunda callback (EarlyStopping) para o processo de treino e restaura os melhores pesos quando a métrica monitorizada (val_loss) deixar de melhorar.
Agora podemos iniciar o treino do nosso modelo:

No código acima, passamos o conjunto de treino, o conjunto de validação, as callbacks e o número de epochs. Cada epoch representa uma passagem completa por todo o dataset de treino. No nosso cenário, especificámos que vamos percorrer o dataset de treino 30 vezes, a não ser que a callback EarlyStopping seja chamada. Tem em mente que, para as callbacks definidas, o parâmetro patience indica o número de epochs — ou seja, se a métrica monitorizada não melhorar após 5 epochs consecutivas, a callback EarlyStopping será invocada.
Parabéns, já treinaste o teu modelo! Agora é hora de testá-lo e fazer algumas previsões com ele.
Previsões
Antes de usar o modelo, vamos primeiro descarregar duas imagens — uma de um gato e outra de um cão — e guardá-las. Se estiveres a usar o Google Collab, podes carregá-las clicando no seguinte botão:
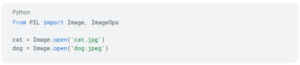
Agora vamos carregar as imagens e processá-las para um formato adequado ao nosso modelo. Para carregar as imagens:
Com as imagens carregadas, vamos convertê-las para escala de cinzentos e redimensioná-las para 128 píxeis de largura e 128 píxeis de altura:
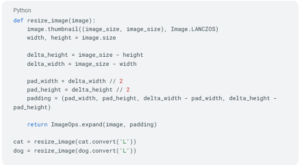
A conversão para escala de cinzentos é feita através da função convert(‘L’), enquanto o redimensionamento é tratado pela função resize_image. À semelhança do que faz o image_dataset_from_directory, a resize_image aplica padding à imagem para evitar deformações.
Agora, os últimos passos são fazer o reshape das imagens e correr o modelo sobre elas. Para o reshape:

As tuas imagens estão agora prontas para serem usadas pelo modelo. Para isso, adiciona duas novas células, uma para cada imagem:

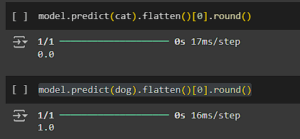
E aqui está: corremos o nosso modelo com as duas imagens. Esperemos que tenha devolvido 0 para a imagem do gato e 1 para a imagem do cão. Se não foi esse o caso, o modelo pode precisar de um pouco mais de treino 😅
Conclusão
Como vimos, o universo da IA é vasto e repleto de nuances e conceitos. Esperemos que este artigo não só tenha ajudado a perceber melhor como a IA evoluiu e como funciona, mas também te tenha inspirado a aprofundar o tema. Lembra-te: apesar de extenso, este artigo apenas arranhOU a superfície — há muito mais para aprender e explorar.
Pedro Oliveira
Lead Web Developer