Uma Introdução Completa à Visão Computacional com IA

Nicholas Carvalho
AR/VR
22 min read • May 21, 2026
A Computer Vision evoluiu de uma experiência pioneira em 1957 para uma das áreas mais transformadoras da inteligência artificial nos dias de hoje. Neste guia, exploramos os fundamentos: a sua história, como funciona, as principais tarefas e as aplicações no mundo real que estão a moldar indústrias a nível global.

banner
Introdução aos fundamentos e exemplos de Computer Vision
Neste artigo vamos fazer uma introdução aprofundada ao computer vision — uma área que tem ganho enorme relevância nos últimos anos — e explorar o que é possível fazer com ela. Para isso, vamos começar por perceber o que é, de onde vem e quais as suas aplicações. Vamos a isso.
O que é?
Computer vision é uma área da inteligência artificial (IA) que utiliza machine learning e redes neurais para ensinar máquinas a extrair informação significativa de imagens digitais, vídeos e outros inputs visuais, e a tomar decisões ou recomendar ações com base no que “veem”.
Funciona de forma semelhante à visão humana, mas com uma diferença fundamental: os seres humanos têm o privilégio de uma vida inteira de contexto. Aprendemos a distinguir objetos ao longo de anos de experiência e conhecimento transmitido de geração em geração, estimamos distâncias com os dois olhos, reconhecemos movimento e detetamos anomalias numa imagem com base na memória e nas experiências passadas. O computer vision treina máquinas para executar estas mesmas funções, mas em muito menos tempo, utilizando câmaras em vez de olhos. Um sistema treinado para inspecionar objetos ou monitorizar um produto consegue analisar milhares deles por minuto, libertando os humanos de trabalho repetitivo e monótono — e rapidamente supera as capacidades humanas nessas tarefas.

Breve história
Em 1957, no American National Institute for Standards and Technology, um grupo de engenheiros liderado por Russell Kirsch conseguiu fazer o primeiro scan digital de uma imagem. A imagem era do filho bebé de Russell e tornou-se tão famosa que a revista Life a incluiu num artigo sobre as 100 imagens que mudaram o mundo. O original encontra-se hoje no Portland Art Museum.
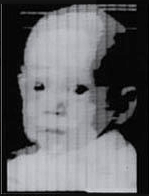
Em 1959, dois neurofisiologistas, David Hubel e Torsten Wiesel, ficaram interessados na forma como o cérebro interpreta estímulos visuais. Decidiram fazer uma experiência com o córtex visual primário de um gato: usando elétrodos, estudaram a ativação de neurónios enquanto mostravam imagens ao animal. Concluíram que existem neurónios simples e complexos e que o processamento visual começa com estruturas básicas — linhas e contornos. Mais tarde, em 1982, o neurocientista britânico David Marr expandiu este estudo, defendendo que o processo de reconhecimento visual tem uma estrutura hierárquica, começando pelo reconhecimento de conceitos fundamentais e evoluindo para a construção de um mapa tridimensional da imagem. Estas hipóteses serviram de alicerces para o primeiro sistema de reconhecimento visual.
Na sua tese de doutoramento em 1963 no MIT, Lawrence Roberts — considerado o pai do computer vision — apresentou um processo para obter informação sobre um objeto 3D a partir de uma imagem 2D. Mais tarde, foi trabalhar para a DARPA e participou no desenvolvimento da Internet.
Em 1979, o cientista informático japonês Kunihiko Fukushima desenvolveu uma rede artificial para reconhecimento de padrões, composta por camadas convolucionais que tratavam uma parte da imagem como um todo, preservando assim a dependência mútua entre pixels vizinhos. Chamou-lhe Neocognitron, e é indubitavelmente a origem das redes que ainda hoje dominam o mundo do reconhecimento visual automático.
Em 1989, o cientista informático Yann LeCun aplicou um famoso algoritmo de treino a uma rede baseada no Neocognitron e utilizou-o com sucesso para ler e reconhecer códigos postais. É também responsável por um dos datasets mais conhecidos em machine learning: o dataset MNIST de dígitos escritos à mão.
O maior avanço aconteceu em 2012, quando a AlexNet reduziu drasticamente a taxa de erro na classificação de objetos no dataset ImageNet. Este dataset foi criado em 2010, impulsionado pela evolução dos algoritmos de processamento de imagem, e é composto por mais de um milhão de imagens divididas em 1000 classes de objetos do quotidiano (animais, tipos de bolas, meios de transporte, etc.).
A partir daí, a tecnologia de computer vision nunca parou de crescer, originando novas áreas de estudo e desenvolvimento como identificação, deteção, reconhecimento, tracking e segmentação.
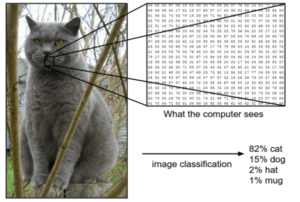
Como funciona?
Um sistema de computer vision segue geralmente três etapas principais:
- Aquisição de imagem
O sistema começa por capturar dados visuais através de câmaras, sensores ou scanners.
- Processamento de imagem
As imagens brutas são limpas e preparadas. Isto pode incluir ajustar o brilho, remover ruído, melhorar o contraste ou redimensionar a imagem. Os computadores veem imagens como grelhas de píxeis, cada um com valores numéricos que representam cor e luminosidade.
- Compreensão da imagem
É aqui que o sistema interpreta o que vê, recorrendo a machine learning:
- Feature Extraction: o sistema procura padrões visuais importantes — contornos, formas, cores, texturas.
- Aprendizagem e Reconhecimento: usando modelos treinados como as Convolutional Neural Networks (CNNs), o sistema compara essas features com padrões conhecidos e aprende a identificar o que vê (por exemplo, “carro”, “pessoa”, “tumor”).
- Tomada de Decisão: por fim, o sistema age com base no que reconheceu — como detetar um defeito, identificar um rosto, ou indicar a um carro autónomo como deve manobrar.
Tecnologias-chave
- Deep Learning: usa redes neurais com múltiplas camadas para aprender padrões automaticamente a partir de dados.
- Convolutional Neural Networks (CNNs): redes neurais especialmente concebidas para análise de imagens.
- Machine Learning: fornece os métodos para que os sistemas melhorem à medida que processam mais dados.
Tarefas Comuns em Computer Vision
Vamos agora explorar algumas das tarefas mais comuns em computer vision, incluindo a sua história, os mecanismos subjacentes e as áreas de aplicação.
1. Image Classification
Definição: Image classification é a tarefa de atribuir um único rótulo a uma imagem inteira, com base nos objetos ou cenas que contém. O objetivo é determinar o que está na imagem, sem especificar a localização ou quantidade de objetos. É a tarefa mais fundamental em computer vision e serve de base para tarefas mais complexas como a deteção de objetos.
História: Nas décadas de 1960 e 1970, os investigadores recorriam a técnicas simples de reconhecimento de padrões, usando features criadas manualmente como contornos, cantos e texturas. Estes sistemas conseguiam distinguir formas básicas ou letras, mas tinham dificuldade com imagens naturais mais complexas.
Nas décadas de 1980 e 1990 foram desenvolvidas features mais sofisticadas, como o SIFT (Scale-Invariant Feature Transform) e o HOG (Histogram of Oriented Gradients). Estas representações mais robustas dos objetos, combinadas com classificadores clássicos de machine learning como Support Vector Machines (SVMs) ou k-Nearest Neighbors, tornaram a image classification significativamente mais fiável.
Em 2012, a AlexNet — uma deep convolutional neural network — venceu o ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Pela primeira vez, redes profundas treinadas de ponta a ponta em grandes datasets superaram amplamente os métodos tradicionais.
Como funciona:
- As imagens de entrada são pré-processadas (redimensionadas, normalizadas).
- As CNNs extraem features hierárquicas: de baixo nível (contornos, cantos), nível médio (texturas, padrões) e alto nível (partes de objetos).
- Uma camada fully connected ou um classificador prevê uma probabilidade para cada categoria.
- A categoria com maior probabilidade é atribuída como rótulo.
Aplicações:
- Deteção de doenças em exames médicos (radiografias, RMN).
- Organização de imagens em e-commerce ou redes sociais.
- Etiquetagem automática em aplicações de fotografia.
2. Object Detection
Definição: Object detection não se limita a identificar objetos numa imagem — localiza-os também através de bounding boxes. Ao contrário da classificação, a deteção diz-te tanto o que está presente como onde está.
História: As primeiras técnicas de object detection surgiram no final do século XX, com o trabalho pioneiro de Viola e Jones em 2001. O seu sistema usava Haar-like features combinadas com um classificador AdaBoost para detetar rostos em tempo real — uma conquista notável para a época. Na década de 2010, as CNNs foram introduzidas na deteção de objetos. A R-CNN, apresentada em 2014, combinou propostas de regiões com deep features, melhorando drasticamente a precisão.
Como funciona:
- Os modelos percorrem a imagem com uma janela de deteção a múltiplas escalas, ou usam anchor boxes para prever objetos.
- Os feature maps são analisados por CNNs para classificar e regredir bounding boxes.
- Abordagens modernas como YOLO (You Only Look Once) e Faster R-CNN realizam a deteção numa única passagem ou com propostas de regiões.
Aplicações:
- Veículos autónomos: deteção de peões, carros e sinais de trânsito.
- Videovigilância: deteção de intrusos ou comportamentos anómalos.
- Retalho: monitorização de stock em prateleiras.
3. Image Segmentation
Definição: A image segmentation divide uma imagem em múltiplos segmentos, frequentemente ao nível do píxel, para identificar contornos e formas de objetos. Proporciona uma compreensão mais detalhada do que a simples deteção.
História: Os primeiros métodos, nas décadas de 1980 e 1990, baseavam-se em thresholding, deteção de contornos e técnicas de region-growing. Funcionavam em cenários controlados, mas eram frágeis com imagens do mundo real.
Na década de 2000, métodos baseados em grafos como Normalized Cuts e Conditional Random Fields (CRFs) melhoraram a segmentação ao considerar as relações entre píxeis. A era do deep learning trouxe arquiteturas como U-Net (2015) e Mask R-CNN (2017), que permitiram segmentação semântica e por instâncias ao nível do píxel.
Tipos:
- Semantic segmentation: atribui a cada píxel um rótulo de classe (por exemplo, estrada, céu, carro).
- Instance segmentation: distingue entre diferentes instâncias da mesma classe (por exemplo, dois carros separadamente).
Como funciona:
- Arquiteturas baseadas em CNNs (U-Net, Mask R-CNN) aprendem a prever máscaras ao nível do píxel.
- Cada píxel é rotulado, criando mapas detalhados de objetos ou regiões.
Aplicações:
- Condução autónoma: segmentação de estradas, faixas e peões.
- Imagiologia médica: delimitação de tumores ou órgãos.
- Realidade aumentada: separação de objetos dos fundos.
4. Object Tracking
Definição: Object tracking é o processo de monitorizar as posições de objetos ao longo de frames consecutivos de vídeo. Ao contrário da deteção, que processa cada frame de forma independente, o tracking preserva a identidade dos objetos ao longo do tempo.
História: As abordagens clássicas das décadas de 1970 e 1980 usavam filtros de Kalman, filtros de partículas ou template matching, que conseguiam prever movimento mas eram limitados por oclusão e variações de iluminação. Trackers baseados em features, como o Kanade-Lucas-Tomasi (KLT), melhoraram a robustez ao rastrear keypoints em vez de objetos inteiros. Com o deep learning, surgiram trackers como o DeepSORT e trackers baseados em redes Siamese, que permitem tracking em tempo real mesmo em cenas muito movimentadas.
Como funciona:
- A deteção fornece as localizações iniciais dos objetos.
- Algoritmos de tracking (filtro de Kalman, SORT, DeepSORT) preveem posições futuras e associam deteções entre frames.
Aplicações:
- Análise desportiva: tracking de jogadores ou bolas.
- Videovigilância: seguimento de pessoas ou veículos em movimento.
- Robótica: seguimento de alvos em movimento em tempo real.
5. Optical Character Recognition (OCR)
Definição: O OCR é o processo de detetar, segmentar e reconhecer texto em imagens para o converter em texto legível por máquina.
História: As primeiras iniciativas significativas no desenvolvimento de máquinas capazes de “ler” texto remontam às décadas de 1920 e 1930. Nas décadas de 1980 e 1990, abordagens baseadas em features combinadas com classificadores de machine learning melhoraram a precisão. O OCR moderno tira partido do deep learning, nomeadamente de modelos baseados em LSTM e CNN, capazes de lidar com manuscritos, fontes variadas e até texto em cenas naturais. Hoje, o OCR alimenta sistemas de digitalização de documentos, reconhecimento de matrículas e apps de tradução em realidade aumentada.
Como funciona:
- Detetar regiões que contêm texto.
- Segmentar linhas, palavras e caracteres.
- Usar reconhecimento de padrões ou deep learning para classificar cada carácter.
- Reconstruir a sequência de texto.
Aplicações:
- Digitalização de documentos impressos.
- Reconhecimento automático de matrículas.
- Tradução de texto em imagens ou aplicações de AR.
6. Pose Estimation
Definição: A pose estimation deteta e prevê a posição de keypoints em humanos, mãos ou rostos, representando a localização de articulações ou pontos de referência.
História: A década de 2000 trouxe as pictorial structures, que representavam o corpo como partes ligadas com modelos probabilísticos. O deep learning revolucionou a pose estimation a partir do DeepPose em 2014, que passou a regredir diretamente as coordenadas das articulações usando CNNs. O OpenPose e outros sistemas modernos permitem a estimação de pose 2D e 3D em tempo real para múltiplas pessoas, com aplicações em gaming, fitness e monitorização de segurança.
Como funciona:
- CNNs ou redes baseadas em heatmaps preveem as coordenadas dos keypoints.
Aplicações:
- Apps de fitness: monitorização de exercícios e postura.
- Gaming: captura de movimento para avatares.
- Monitorização de segurança em ambientes de trabalho.
7. Geração e Melhoria de Imagens
Definição: A geração de imagens refere-se à criação de novas imagens do zero ou à modificação de imagens existentes com recurso a IA. A melhoria de imagens aumenta a qualidade, remove ruído ou aumenta a resolução.
O desenvolvimento das Generative Adversarial Networks (GANs) em 2014 permitiu às máquinas gerar imagens completamente novas, produzir outputs de super-resolução e realizar style transfer. Hoje, as imagens geradas por IA são usadas em entretenimento, arte, ambientes virtuais e restauro de imagens antigas ou de baixa resolução.
Como funciona:
- Modelos generativos como as GANs criam imagens realistas.
- CNNs e redes baseadas em transformers realizam super-resolução ou denoising.
Aplicações:
- Melhoria de fotos de baixa resolução.
- Geração de avatares realistas ou obras de arte.
- Preenchimento de partes em falta de imagens (inpainting).
8. Análise Facial
Definição: A análise facial deteta, reconhece e interpreta rostos humanos, incluindo identidade, emoção e outros atributos.
Na década de 1960, sistemas como Eigenfaces e Fisherfaces usavam projeções lineares para reconhecimento, com resultados modestos em condições controladas.
A década de 2000 trouxe deteção de rostos em tempo real com Haar cascades, enquanto abordagens baseadas em deep learning como FaceNet, DeepFace e ArcFace oferecem hoje reconhecimento altamente preciso em diversas poses, condições de iluminação e expressões.
Como funciona:
- A deteção de rostos localiza as faces na imagem.
- A extração de features converte os rostos em embeddings ou keypoints.
- O reconhecimento ou classificação identifica indivíduos ou atributos.
Aplicações:
- Segurança: autenticação facial.
- Filtros em redes sociais e aplicações de AR.
- Estudos de mercado: análise das emoções dos clientes.
9. Scene Understanding / Image Captioning
Definição: Scene understanding implica compreender o contexto completo de uma imagem, incluindo objetos, relações entre eles e, por vezes, a geração de descrições textuais (captioning).
Os primeiros sistemas das décadas de 1980 e 1990 baseavam-se em métodos rule-based ou features de baixo nível. As abordagens modernas combinam CNNs para extração de features com RNNs ou modelos baseados em Transformers para gerar descrições textuais.
Modelos como Show-and-Tell ou Show-Attend-and-Tell conseguem hoje descrever imagens em linguagem natural, tornando o conteúdo visual acessível a utilizadores com deficiência visual e melhorando a pesquisa inteligente de imagens.
Como funciona:
- As CNNs extraem as features da imagem.
- RNNs ou Transformers geram legendas com base nas features visuais.
- O resultado é uma descrição semântica da cena.
Aplicações:
- Apoio a utilizadores com deficiência visual através da descrição de imagens.
- Robôs a navegar em ambientes complexos.
- Etiquetagem automática de imagens para motores de pesquisa.
10. Reconstrução 3D e Estimação de Profundidade
A reconstrução 3D estima a estrutura tridimensional de objetos ou cenas a partir de imagens 2D. A estimação de profundidade prevê a distância de cada píxel em relação à câmara.
A visão estéreo e os métodos de triangulação remontam à década de 1980, enquanto a Structure-from-Motion (SfM) ganhou popularidade nos anos 2000.
Métodos recentes de deep learning, incluindo monocular depth estimation e Neural Radiance Fields (NeRFs), conseguem produzir modelos 3D altamente detalhados a partir de uma ou múltiplas imagens.
Como funciona:
- A visão estéreo usa duas câmaras para calcular a profundidade.
- A monocular depth estimation usa CNNs para prever profundidade a partir de uma única imagem.
- A fotogrametria reconstrói modelos 3D a partir de múltiplas imagens.
Aplicações:
- Robótica e navegação autónoma.
- Realidade aumentada e virtual.
- Arquitetura e preservação de património.
Exemplo Prático
Deteção de Rostos com Haar Cascades no Google Colab
A deteção de rostos é uma das tarefas clássicas em computer vision. Antes do deep learning se tornar o standard, uma técnica muito popular e eficiente eram os Haar Cascade Classifiers — um método introduzido por Viola & Jones que permitia deteção de rostos em tempo real mesmo em hardware simples. Ainda hoje, os Haar cascades continuam a ser úteis para aprendizagem e demonstrações rápidas.
O que são os Haar Cascades?
Um Haar Cascade é um modelo de machine learning treinado para detetar padrões específicos — neste caso, rostos. Utiliza:
- Haar-like features (padrões simples de contornos e linhas)
- Integral images (para computação muito rápida)
- Uma estrutura em cascata (que rejeita rapidamente regiões sem rosto)
Isto torna o método leve e rápido.
Como funciona (simplificado):
- Converter a imagem de entrada para escala de cinzentos (mais rápido e com menos computações)
- Percorrer a imagem com uma janela deslizante
- Classificar cada região como “rosto” ou “não é rosto”
- Marcar os rostos detetados com retângulos
Abaixo encontras um tutorial pronto a usar no Google Colab, com todos os passos necessários.
Primeiro, importamos algumas bibliotecas que vamos utilizar neste exemplo:
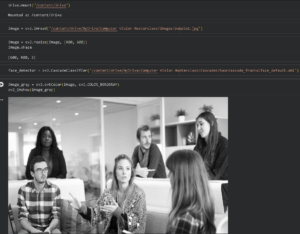
De seguida, conectamos ao Google Drive, que contém o modelo pré-treinado e alguns datasets, para carregar e processar a imagem (podes encontrar este modelo AQUI ).
Vamos redimensionar a imagem para o tamanho aceite pelo modelo de IA e convertê-la para escala de cinzentos, de forma a eliminar a variável da cor e reduzir o tempo de treino e/ou deteção.
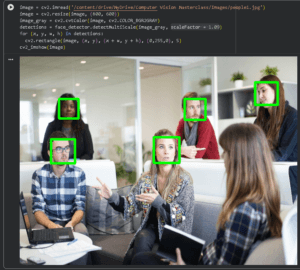
Após testar o modelo e analisar os resultados, verificamos que detetou incorretamente 6 rostos em vez de 5.

Os Haar Cascades percorrem a imagem a múltiplas escalas, porque os rostos podem aparecer pequenos ou grandes. Em vez de redimensionar a janela de deteção, o OpenCV normalmente redimensiona a imagem inteira repetidamente e procura rostos em cada escala. O scaleFactor diz ao OpenCV quanto deve encolher a imagem de cada vez.
Com esta informação, podemos alterar o scale factor de 1 para 1.09, obtendo assim 5 deteções corretas.
Conclusão
Neste artigo explorámos os fundamentos do Computer Vision, as suas diversas aplicações e como pode ser utilizado em situações do mundo real. A principal conclusão é que o Computer Vision não é apenas teoria — está a ser ativamente utilizado para resolver problemas complexos, desde diagnósticos médicos e carros autónomos até à automação industrial e análise de retalho. O nosso objetivo foi não só proporcionar uma compreensão sólida do que é o Computer Vision, mas também inspirar-te a explorar o seu potencial e perceber como pode beneficiar o teu trabalho ou negócio.
Se este tema despertou a tua curiosidade e queres saber mais sobre Inteligência Artificial, consulta o nosso artigo “Introdução à Inteligência Artificial”.
Nicholas Carvalho
AR/VR